Rei Sanchez-Arias
Teaching Associate Professor and
MADS Faculty Director
The University of North Carolina
at Chapel Hill
About me
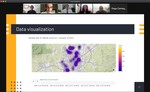
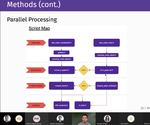
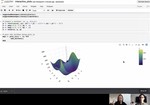
I am a Data Science Faculty at the University of North Carolina at Chapel Hill (UNC), and serve as the Faculty Director for the Master of Applied Data Science (MADS) program in the School of Data Science and Society (SDSS). Prior to moving to UNC, I was an Associate Professor of Data Science in the Department of Data Science and Business Analytics (DSBA) at Florida Polytechnic University (Florida Poly). I also served as the Assistant Chair of DSBA, working in all department operations, including but not limited to: curriculum design, course assessment, faculty recruitment, student advising, and other institutional activities. Before joining Florida Poly, I served as the Program Director for the MS in Big Data Analytics in the School of Science at St. Thomas University (STU) in Miami, after starting my career as an Assistant Professor of Applied Mathematics at Wentworth Institute of Technology (WIT) in Boston. I completed a Postdoctoral Researcher appointment for the Army High Performance Computing Research Center (AHPCRC) at The University of Texas at El Paso (UTEP) in collaboration with a group at Stanford University. Research projects for the AHPCRC involved the development of numerical optimization and parameter estimation algorithms, reduced-order modeling, and large-scale data analytics.
Interests
- Data Science Education
- Statistical Learning
- Data Mining
- Numerical Optimization
Education
-
PhD and MS in Computational Science
The University of Texas at El Paso
-
BSc in Mathematics
Universidad del Valle (Colombia)